 英語研究室<<
英語研究室<<コーパス活用法(2)
コーパスの解析と利用法
前回はコーパスとして利用するファイルの収集方法について説明しましたが、今回は蓄積したデータの利用法に焦点を当てます。基本的にはコーパスを検索してその結果を分析することになります。これを翻訳業務に応用する場合、キーワードの抽出とコロケーションの確認が主になるでしょう。語彙の出現頻度を調べることにより、文書に頻繁に出現する用語を拾い出して事前に訳語リストを作成することができます。また、コロケーションを調べて適切な語句の組み合わせを行うことで、ネイティブ並の英文を書くことも可能になります。さらに対訳コーパスを解析することにより素早く適切な訳文の作成や訳文のチェックを効率的に行うことができるようになります。
これらの検索・解析を行うツールとして「コンコーダンサ」と呼ばれるものがあります。細かい条件を付けて検索を行うことができ、結果をわかりやすく表示してくれます。また、簡単な操作で複雑な統計処理をしてくれるものもあります。デジタル化された文書を翻訳する際には、このようなツールを使って迅速に分析し、文書のタイプに応じて適切に対処することが大切です。
コンコーダンサの紹介と使い方
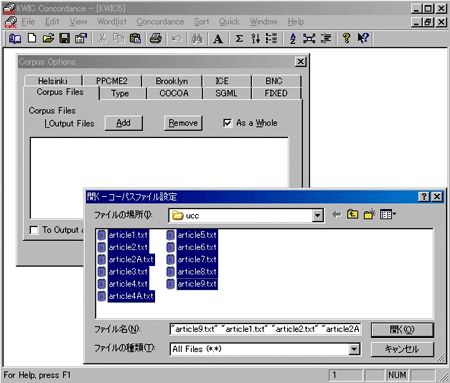
フリーソフトのKWIC Concordance for Windows(作者:塚本 聡氏 http://www.chs.nihon-u.ac.jp/eng_dpt/tukamoto/kwic.html)を使えば、簡単に単語リストやインデックスを作成できます。頻度順のリストからキーワードを抽出し、インデックスを作成することで、特定の単語が文書のどの部分にどのくらい出現しているかを知ることができます。それでは早速「単語リスト」を作成してみましょう。最初にコーパスファイルを設定します。[Corpus Set]ボタンをクリックしてセットアップ画面を開き、さらに「Corpus Files」タブを選択します。ここで[Add]ボタンをクリックしてファイルを選択します。一度に複数のファイルを選択できます。「As a Whole」にチェックを入れると指定したすべてのファイルを対象にすることができます。ここでは前回ダウンロードした「Uniform Commercial Code」を設定してみました。(図1)
(図1)KWIC Concordance for Windows
リストの作成は[Wordlist]→[Wordlist]をクリックするだけです。ABC順に表示されます。出現頻度の高い順に表示するには[Descending Wordlist]をその逆は[Ascending Wordlist]をクリックします。(図2)
(図2)Wordlistメニュー
ABC順にワードリストを表示してみました(図3)。単語の右側の数字が出現回数です。「acceptance」が228回出現しているのが目につきます。出現頻度の高い順に表示すれば簡単にキーワードを抽出できます。キーワードがどのような文脈に出現しているか見ることで、どのような語句との組み合わせが適切かといったコロケーションの情報を得ることができます。
(図3)ワードリスト

シェアウエアのTEXTANA(作者:赤瀬川史朗氏 http://www.biwa.ne.jp/~aka-san/index.htm)は本格的なコンコーダンサで、KWIC表示、頻度集計、コロケーション統計など多機能です。検索語と文脈を合わせて出力するのがコンコーダンスですが、検索語を中心に置いて含まれる行ごと表示する形式をKWIC(key word in context)コンコーダンスと呼びます。ここではTEXTANA Learning Edition を使用します。
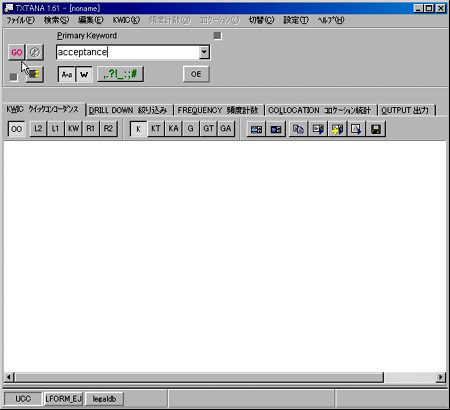
それでは簡単に使い方を見てみましょう。ここでも、コーパス用のファイルの設定を最初に行います。[ファイル]→[検索ファイルセット登録]で指定します。複数のファイルセットを登録することができ、割り当てたファンクションキーで簡単に切り替えができます。先ほどと同じ「Uniform Commercial Code」のファイルをセットします。クイックコンコーダンスの画面を開き、Primary keywordに「acceptance」と入力して、「GO」ボタンをクリックします。(図4)
(図4)TEXTANA Learning Edition
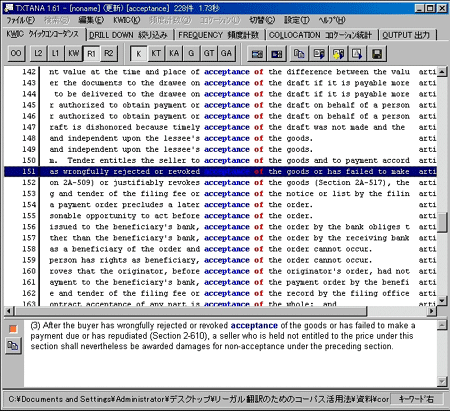
228件の検索結果が表示されました。ここで「R1」ボタンをクリックしてキーワードの右側の単語でソートしてみました(図5)。前置詞は「of」が圧倒的に多いのがわかります。下のウインドウには、選択したラインのセンテンスが全文表示されています。
(図5)KWICコンコーダンス
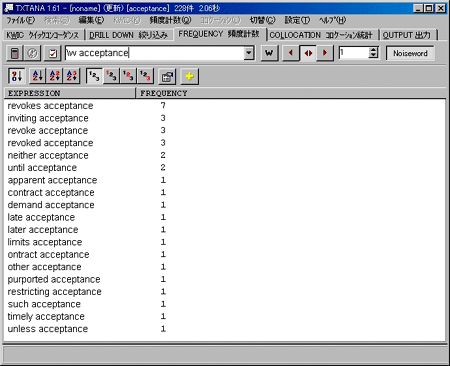
今度は「頻度計数」タブをクリックして、キーワード入力欄の▼をクリックして表示された中から「w acceptance」を選択します。これはキーワードの左側一番目の単語について頻度を計数することになります。そのままだと冠詞や前置詞などが必ず上位に来てしまうので「Noiseword」ボタンを押下してそれらの単語を検索対象からはずします。このようにして「計数開始ボタン」をクリックすると、http://www.biwa.ne.jp/~aka-san/index.htmのように検索結果が表示されました。「revoke acceptance」という表現が多いのがわかります。
(図6)頻度計数画面
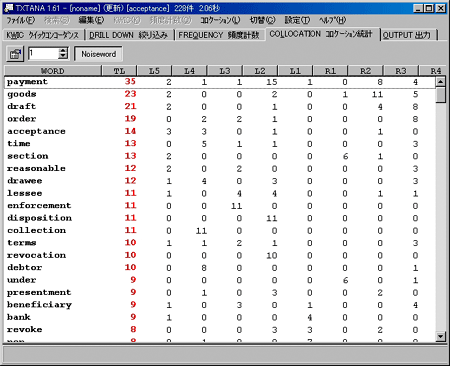
最後にコロケーション統計を見ておきましょう。コロケーション統計画面で「Noiseword」ボタンを押下しておいて、「TL」ボタンをクリックします。キーワード前後5語の合計の頻度が高い順に表示されました(図7)。「acceptance」と「payment」が共に使われることが多いことがわかります。
(図7)コロケーション統計画面
対訳データベースとgrep検索
最近では翻訳ソフトを使用する翻訳者も多くなりました。それでも、翻訳ソフトの出力する訳文は役に立たないと、毛嫌いする人も少なくありません。ここで少し頭を切り換えて、翻訳ソフトを「対訳コーパス作成ツール」と捉えてみたらいかがでしょうか。業務用の翻訳ソフトには対訳エディタと対訳データベース機能が搭載されています。対訳エディタで翻訳作業を行えば、どんどん対訳データが蓄積されて行きます。出力される訳文もまったく使えないということはなく、ユーザ辞書をしっかり調整すれば、下訳として十分活用できます。ただし、対訳データベース(翻訳メモリ)を、自動的に適用しようとしてもなかなかうまくいきません。特に、法律関係の複雑な文はほとんどマッチしないと考えた方がいいでしょう。それよりも、秀丸エディタやWZエディタなどのテキストエディタに備わっているgrep検索を使用するのが実用的です。この検索を行うと、複数のファイルから検索語を含む行が抽出されて一覧表示されます。また、任意の行をクリックするともとの文書がポップアップ表示されます。
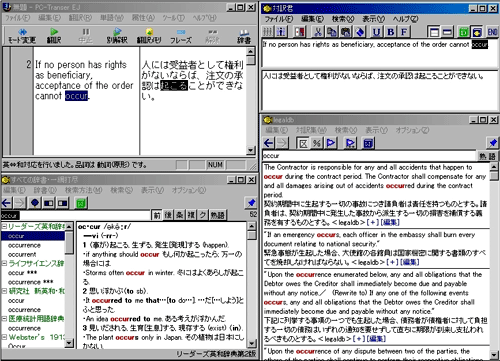
さらに、辞書と対訳ファイルを簡単に設定して高速で検索してくれる「対訳君」(株式会社MCL http://www.mcl-corp.jp/taiyaku/taiyaku-outline.htm)のような検索ソフトと組み合わせて使えば効率よく翻訳できるでしょう。(図8)
(図8)PC-Transerと対訳君を組み合わせて活用する
コーパスを利用する方法はまだたくさんありますが、最終的にはコーパスの質と検索結果から情報を読み取る力が大切だということを忘れないようにしたいものです。(2005年12月)