 丂塸岅尋媶幒<<
丂塸岅尋媶幒<<僐乕僷僗妶梡朄(1)
丂嵟嬤偱偼丄僀儞僞乕僱僢僩偺偍偐偘偱揹巕壔偝傟偨朄椷傗宊栺彂偺僼傽僀儖傪娙扨偵庤偵擖傟傞偙偲偑偱偒傞傛偆偵側傝傑偟偨丅Google側偳偺専嶕嶔婡擻傪巊偊偽丄昁梫偲偡傞暥椺傪尒偮偗傞偙偲偑偱偒傑偡丅偨偩丄扵偟摉偰偨僼傽僀儖傪僟僂儞儘乕僪偟偰傕丄廫暘偵妶梡偡傞曽朄傪抦傜側偄偙偲偑懡偄傛偆偱偡丅丂偦偙偱丄偙偺傛偆側僼傽僀儖傪拁愊偟偨傕偺傪僐乕僷僗乮揹巕壔偝傟偨戝婯柾側尵岅帒椏乯偲峫偊丄東栿偺嵺偵偳偺傛偆偵妶梡偡傟偽椙偄偐丄曋棙側僜僼僩僂僄傾偺徯夘傕岎偊偰夝愢偟偰傒偨偄偲巚偄傑偡丅
丂乽東栿儊儌儕乿傛傝乽僐乕僷僗乿
丂東栿偺偨傔偺僨乕僞儀乕僗偲尵偊偽丄偡偖偵乽東栿儊儌儕乿偲摎偊傞東栿幰偑懡偄偲巚偄傑偡丅妋偐偵孞傝曉偟偺懡偄斾妑揑扨弮側峔憿偺暥復偺応崌偼桳岠偱偡偑丄宊栺彂側偳偺儕乕僈儖暥彂偼暋嶨側忋丄東栿扨埵乮捠忢偼僙儞僥儞僗乯偱搊榐偝傟偨僨乕僞儀乕僗偱偼専嶕偟偰傕儅僢僠偡傞偙偲偼傎偲傫偳偁傝傑偣傫丅丂儕乕僈儖東栿偵栶棫偮東栿僨乕僞儀乕僗傪峫偊傞偲丄塸暥偩偗傪廤傔偨僐乕僷僗偁傞偄偼丄尨暥偲栿暥傪岎屳偵婰擖偟偨暥彂傪拁愊偟偨僐乕僷僗傪偆傑偔専嶕偟偰嶲徠偱偒傞傛偆偵偟偨曽偑岠壥揑偱偡丅
丂僨乕僞偺廂廤
丂尵岅妛偱梡偄傜傟傞僐乕僷僗偼丄悽奅弶偺揹巕僐乕僷僗偱100枩岅廂榐偺Brown Corpus傪偼偠傔偲偟偰丄3壄悢愮枩偺岅悢傪桳偡傞The Bank of English側偳悢懡偔偁傝傑偡丅偨偩丄偙偙偱偼尵岅妛揑偵尩枾側暘愅傪偡傞偺偱偼側偔丄儕乕僈儖東栿偵栶棫偰傞偙偲偑栚揑偱偡偐傜丄僐乕僷僗傪乽宯摑揑偵廤傔傜傟偨婡夿壜撉僥僉僗僩宍幃僨乕僞偺廤愊乿偲尷掕偟偰丄朄椷傗宊栺彂偺僥儞僾儗乕僩側偳傪廂廤偡傞偙偲偵偟傑偡丅丂傑偢丄偙傟傑偱偵東栿偟偨暥彂側偳庤帩偪偺僼傽僀儖偑偁傟偽暘椶偟偰曐懚偟傑偡丅揔摉側僪儔僀僽偵乽corpus乿側偳偲偄偆柤慜偱僼僅儖僟傪嶌惉偟丄偦偺拞偵偝傜偵僇僥僑儕暿偺僼僅儖僟傪嶌偭偰僼傽僀儖傪惍棟偟偰峴偒傑偡丅偙傟偩偗偱偼彮側偡偓傑偡偺偱丄偁偲偼WEB僒僀僩偐傜僟僂儞儘乕僪偟偰廤傔偰傒傑偟傚偆丅
丂僟僂儞儘乕僪偺曽朄
丂朄椷傗宊栺彂偺僥儞僾儗乕僩傪僟僂儞儘乕僪弌棃傞WEB僒僀僩偼偨偔偝傫偁傝傑偡丅Google側偳巊偭偰専嶕偟偰偔偩偝偄丅桳椏偺僒乕價僗傕偁傝傑偡偑丄嵟弶偼柍椏偱僟僂儞儘乕僪偱偒傞傕偺偱帋偡偲椙偄偱偟傚偆丅丂椺偊偽丄乽"Uniform Commercial Code"乿偲専嶕憢偵擖椡偟偰専嶕偟偰傒傑偡丅Google偺応崌丄嬪偱専嶕偡傞偲偒偼偙偺傛偆偵僋僆乕僥乕僔儑儞丒儅乕僋傪晅偗傑偡丅
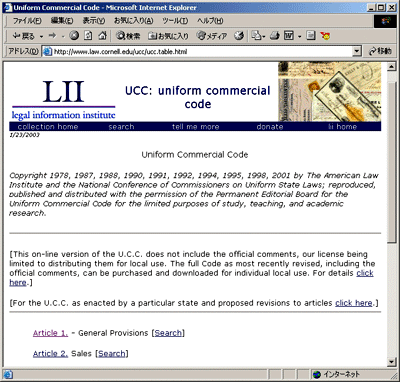
専嶕寢壥偺拞偺堦斣栚偵昞帵偝傟偨乽www.law.cornell.edu/ucc/ucc.table.html乿傪奐偔偲丄Article 儗儀儖偺栚師偵側偭偰偄傞偺偱丄偝傜偵乽Article 1.乿傪僋儕僢僋偡傞偲PART偍傛傃僙僋僔儑儞儗儀儖偺栚師偑昞帵偝傟傑偟偨乮恾1乯丅
乽Section 1-101乿偺儕儞僋傪僋儕僢僋偡傞偲丄乽PART 1.乿偺杮暥偑昞帵偝傟傞偺偱丄[僼傽僀儖]仺[柤慜傪晅偗偰曐懚]偱乽僼傽僀儖偺庬椶乿傪乽Web儁乕僕丄HTML偺傒乿偵偟偰曐懚偟傑偡丅
乮恾1乯
丂僟僂儞儘乕僪丒僣乕儖偺棙梡
丂捠忢偼偙偺傛偆偵僼傽僀儖傪堦偮堦偮曐懚偟偰峴偒傑偡偑丄悢偑懡偄偲帪娫偺偐偐傞柺搢側嶌嬈偲側傝傑偡丅偦偙偱丄僟僂儞儘乕僪偡傞僒僀僩偺峔憿傪堦捠傝挷傋偨傜僟僂儞儘乕僪丒僣乕儖傪巊偭偰堦婥偵帺摦揑偵僟僂儞儘乕僪偟偰偟傑偄傑偟傚偆丅丂GetHTMLW (YutakaEndo巵 http://www.vector.co.jp/soft/dl/win95/net/se077067.html乯偼儂乕儉儁乕僕傪傑傞偛偲 Get 偟偰丄僆僼儔僀儞偱墈棗偡傞僼儕乕僜僼僩偱偡丅
丂偙偙偱Uniform Commercial Code偺儁乕僕傪椺偵偟偰丄巊梡朄傪娙扨偵愢柧偟傑偡丅
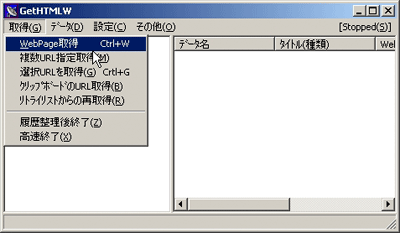
(1) GetHTMLW傪婲摦偟偰丄[庢摼]仺[WebPage庢摼]傪僋儕僢僋偟傑偡丅乮恾2乯
乮恾2乯
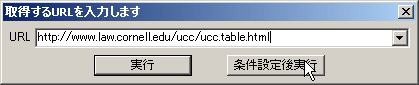
(2) 乽庢摼偡傞URL傪擖椡偟傑偡乿夋柺偑昞帵偝傟偨傜丄愭傎偳偺http://www.law.cornell.edu/ucc/ucc.table.html傪擖椡偟偰[忦審愝掕屻幚峴]傪僋儕僢僋偟傑偡丅乮恾3乯
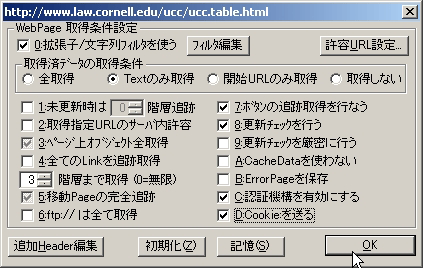
乮恾3乯(3) WebPage庢摼忦審愝掕偱偼丄庢摼偡傞奒憌偩偗曄峏偟傑偡丅偙偺応崌丄擖椡偟偨URL偑乽Uniform Commercial Code乿偺栚師儁乕僕偱丄杮暥偺儁乕僕偼偦傟偐傜2搙儕儞僋傪偨偳偭偨偲偙傠偵偁偭偨偺偱丄2奒憌壓偵偁傞偲峫偊偰丄[3]奒憌傑偱庢摼偵偟偰[OK]儃僞儞傪僋儕僢僋偟傑偡丅乮恾4乯
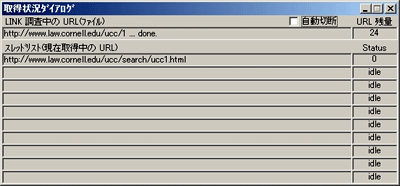
乮恾4乯(4) 庢摼忬嫷僟僀傾儘僌偑昞帵偝傟偰丄僼傽僀儖偑師乆偲僟僂儞儘乕僪偝傟偰峴偒傑偡丅乮恾5乯
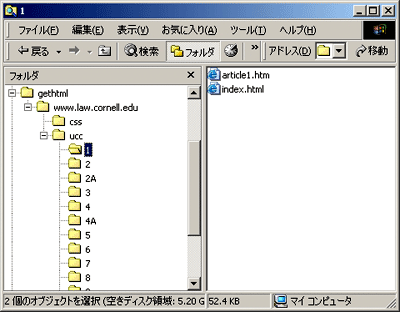
乮恾5乯(5) 庢摼偑姰椆偡傞偲丄尦偺僨傿儗僋僩儕峔憿傪曐偭偨傑傑儘乕僇儖丒僨傿僗僋偵曐懚偝傟傑偟偨丅乮恾6乯
乮恾6乯
丂HTML僼傽僀儖傪僥僉僗僩僼傽僀儖偵曄姺
僟僂儞儘乕僪偟偨HTML僼傽僀儖偵偼僞僌偑晅偄偰偄傞偺偱専嶕偺嵺偵偠傖傑偵側傞偙偲偑偁傝傑偡丅WEB僽儔僂僓偱昞帵偟偰偍偄偰僥僉僗僩宍幃偱曐懚偡傟偽僞僌傪偼偢偡偙偲偑偱偒傑偡偑丄僼傽僀儖悢偑懡偔側傞偲庤娫偑偐偐傝傑偡丅偦偙偱丄HTML偺僞僌嶍彍僣乕儖傪妶梡偟傑偡丅丂乽HtoX32乿乮T-Matsuo巵丂擖庤愭丂http://win32lab.com/fsw/htox.html乯偼僼儕乕偺僞僌嶍彍僜僼僩偱偡丅僪儔僢僌仌僪儘僢僾偡傞偩偗偱HTML僞僌傪嶍彍偱偒傑偡丅傑偨丄EUC丄JIS丄SJIS丄Unicode丄UTF-8偲偄偭偨暥帤僐乕僪傪帺摦敾暿偟偰SJIS偵曄姺偟偰弌椡偟偰偔傟傑偡丅乮恾7乯
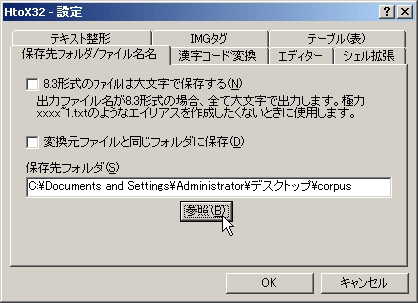
乮恾7乯丂僪儔僢僌仌僪儘僢僾偡傞傑偊偵丄[僆僾僔儑儞]仺[愝掕]偱曐懚僼僅儖僟愭傪擟堄偺傕偺偵曄峏偟偰偍偔偲椙偄偱偟傚偆丅[嶲徠]傪僋儕僢僋偟偰僼僅儖僟傪慖戰偟傑偡丅乮恾8乯
乮恾8乯
丂僟僂儞儘乕僪偱偒傞僼傽僀儖偵偼丄HTML偺懠偵MS-Word傗PDF僼傽僀儖側偳偑偁傝傑偡丅
corpus梡偺僼傽僀儖偼尨懃偲偟偰僥僉僗僩宍幃偵偡傞偺偱丄Word偺応崌偼[僼傽僀儖]仺[柤慜傪晅偗偰曐懚]偱乽僼傽僀儖偺庬椶乿傪乽僥僉僗僩偺傒乿偵偟偰曐懚偟傑偡丅
丂PDF偺応崌偼僥僉僗僩偱曐懚偱偒側偄偺偱丄夋柺忋偱暥帤傪僐僺乕偟偰Word傗僥僉僗僩丒僄僨傿僞側偳偵揬傝晅偗偨忋偱曐懚偟傑偡丅偦偺嵺丄[昞帵]仺[楢懕]偵僠僃僢僋傪擖傟偰偍偐側偄偲暥彂慡懱傪[偡傋偰慖戰]偡傞偙偲偑偱偒側偄偺偱拲堄偑昁梫偱偡丅乮2005擭11寧乯